《Linux 平台高级调试和优化(杭州站)》培训笔记
第一天上午:大局观和 linux 内核源码
内核版本介绍
linux4.19 LTS 版本使用率比较高,发的 GDK8 的盒子就是该版本。linux6.1 LTS 版本将会是下一代主流版本,预测生命力至少 5-10 年。
在网站 https://kernel.org/ 里能看到内核版本分支,mainline 主线分支由 Linus Torvalds 维护,stable 稳定分支由 Greg Kroah-Hartman 维护。
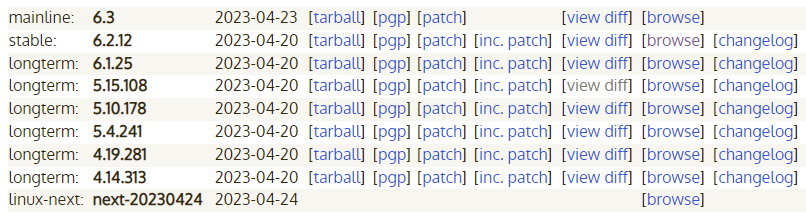
开发者不太愿意紧跟 Linux 内核版本更新,因为一旦升级内核,便涉及到驱动之类的代码需要修改,产生很多编译错误。虽然对于有经验的程序员来说,比较容易排错,但这里面的工作量也很巨大。一直使用旧版本也有缺点,比如有些新特性无法使用,即使将新特性代码 patch 到旧版本,仍不能很好使用。
内核源码重点关注的三部分
内核三大块:驱动(driver)、架构(arch)、纯软件(kernel)。
三大目录
drivers:驱动,外设目录,硬件厂商维护
arch:各架构实现代码,arch 下也有 kernel 目录但主要实现架构相关的汇编代码,和一级目录 kernel 有区别的。
kernel:通用的代码和处理。
tools 目录里,有些工具是运行在用户空间,像 perf 在 kernel 里有基础支持,在 tools 里面有用户态的代码供编译。
ebpf:动态修补 Linux 的机制,一种新技术,老版本内核可能不兼容。挂钩子函数,高性能,可以篡改内核代码。也有不好的影响如钩子太多的话也会影响内核性能。
GUN 和 Linux
GNU:也可以认为是操作系统,发起者 stallman 秉持从上到下,从应用环境开始着手,想创造一套操作系统。比如 GCC、GDB 都是他发起的。
Linux:发起者 Linus 与 stallman 思路相反,从下到上开始,从硬件和内核开始研发。
最终两者结合起来,诞生了当前的 GNU/Linux 操作系统,这是标准叫法,但后来常被简称为 Linux。
空降兵思路:作为一个空降兵,快速到现场作战,针对问题提出不同解决方案。
要想性能快,少和外设打交道,不然速度会变慢,要 IO。
dpdk 库:非常规思路,避免系统调用的开销,把所有操作都弄到用户空间,所以性能比较快,实现用户态加速。贵的网卡就这样做,很快访问,但缺点是不能通用。主要是网络服务,收发包不用切到内核。
第一天下午:两大空间和调试内核代码
在硬件调试方面,有 jtag 和 coresight(arm 提出来的,硬件调试更方便,相比 Intel 性价比更高)两种技术。
x86 架构 32 位 8 个,64 位 16 个寄存器。寄存器太少,编译器代码不好写。寄存器太多,线程切换开销大。
Windows 上调试命令:
- r:查看寄存器
- u:查看汇编
- .sympath:符号表位置
- .reload:重载符号表
- lm:展示 module
openOCD 对接 gdb 或者 dbgengine,risc-v 用的比较多。

arm 拥有非常多的系统寄存器,对于嵌入式和驱动开发,需要关注某些系统寄存器。然后 gdb 不能查看 arm 系统寄存器,windbg 可以。
写程序优化思想,尽量在栈上定义变量,不要用全局变量,多用局部变量。局部相关性原理,数据操作在一小段地址范围,可以直接被 cache 装载,这样速度提高很大。避免大范围地址空间跳动,触发 page fault。
局部变量不初始化,也是有好处,并不要刻板的编程规范,内核代码有很多这种示例。可以 strace 看个简单的程序,发现很多都是 mmap 和 memset 之类的内存操作,有些情况下变量没必要提前赋值初始化。
GDB 使用方法
GDB 调试应用程序比较给力,调试内核代码不太好用。
查看 build-id 符号信息(.note.gnu.build):readelf --notes /bin/ls
info symbol 0xaaaa:查看地址的符号名
run / -R:调试的程序若为 ls,表示传参 ls -R
汇编里的 mmap@plt 含义:编译时先指定,运行时根据 plt 调整位置,运行时链接。
ldd -v /bin/ls:显示详细的动态库信息。
__brk:相当于去内核批发内存,和 mmap 有些类似。
调试信息:微软符号格式是 pdb,开放的是 dwarf 符号,!readelf --debug-dump ./labs/gemalloc/gemalloc
介绍一种 Linux 图形化 gdb 调试方法:用微软 vs 调试 Linux 程序,可以使用 VS 界面的丰富调试功能,也可以跨架构和交叉调试。
vs 调试应用比较好,windbg 调试内核或驱动比较好,需要针对不同场景进行选择。
当前仍存在的技术缺陷:调试器都是基于 CPU 调试,无法调 GPU。GPU 如果访问了某个内存,目前没办法找。像 DMA 和 cache 相关问题,无奈只能上仿真器解决。
handle signal pass:收到 signal 传递给用户程序,不让 gdb 接收。
1 | (gdb) handle SIGINT pass |
gdb+qemu:不能调试硬件、wifi 或 GPU 驱动之类的,只能简单看内核。
第二天:内存管理
各级 cache 速度差:L1:纳秒;L2:十几纳秒;L3:数十纳秒,L3 如果 miss,则可能几百纳秒或毫秒级别。
编写程序时优化思路:写程序充分利用程序局部性原理,将常用的变量 / 数据结构之类的写到一起,访问更快。程序规划好执行热路径和冷路径,比如异常处理函数写到最后。
微软优化思路:将反汇编的热指令和冷指令位置调整,利用 PGO 技术,将程序跑一边,通过插桩分析冷热代码,然后编译器重新编译,将热代码上移,将冷代码下移。
PGO (Profile-guided optimization) 是一种编译优化技术,原理是编译器使用程序的运行时 profiling 信息,生成更高质量的代码,从而提高程序的性能。
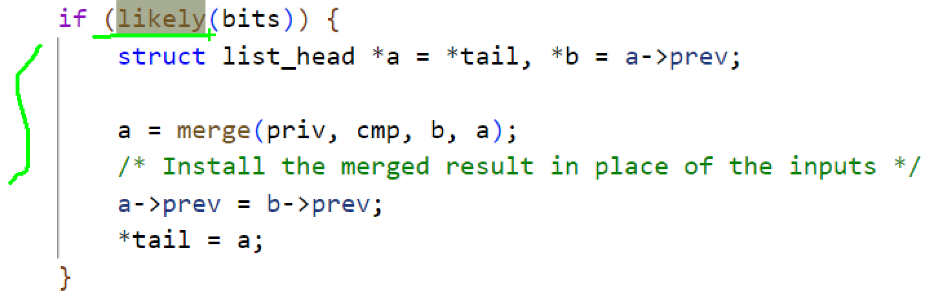
内核里有支持,将热代码标记为 likely。分支预测,优先预测附近,分支预测失败就会污染 cache。
内存分配过程:mmalloc 先分配虚地址,调用 mmset 后初始化,pagefault 后不断挂页,然后就比较慢。不做 memset 就相当于挂一个虚的页表。
time ./a.out:简单看一下时间,不太准确,有波动。
堆内存分配大的话,直接去内核,堆管理器只零售小内存。
循环展开的情况:固定循环变量为 3,则复制 3 份代码顺序执行。有时跟编译器优化有关,可能看不到。
perf record -e page-faults ./a.out:通过捕获 pagefault 事件来分析内存分配情况。
看栈的大小:ulimit -s 8192
cond 2 $_thread!=1:条件断点,线程不等于 1。
内存不对齐导致的错,比如指针显示的地址末位不为 4 倍数,1 或 2 或者 3,说明没有对齐,这样就能通过经验一下子发现。
堆分配内存 8 字节为单位。
gdb 不能单独只调试 coredump 文件,必须跟上主程序。Windows 的 core 文件包含一些摘要信息,可以单独调。另外,分析 core 文件,最好现场环境保持一致。
setjump 和 longjum:保存信息,恢复重新输出一些信息。例如 windows 系统挂掉,并没有直接关闭,再跳一下位置,此时执行指令输出一些报错提示重启信息蓝屏信息。
set disassembly-flavor intel:换汇编成 intel 格式
篡改 PC 指针,跳过当前 sigfalut 指令,强制执行下一条,有时候可能会绕过错误。
看系统中断: cat /proc/interrupts
小于 4096 的都是空指针,小于一个页大小的都是。
进程挂死后,先 ps -aux 找到 pid 为 1111,进入 /proc/1111,然后 cat stack,查看栈。
cat /proc/kallsyms:查看假文件系统。
第三天:调优问题
内核 current 宏变量,内核代码全局可见。
内核代码若定义了 current 变量,编译时则会和内核展开会冲突。比如代码里有 int current = 1; 编译就会奇怪的报错到 get_current () 函数。
常规宏变量都是大写,这里阴差阳错用了小写 current,原因是之前 current 就是全局变量,后来有场景需要,改成了宏,这是最小的代码修改量。
优化思想:插桩 + 统计
perf 通过采样,不准确,统计学理论。
没有 gdb 和其他工具环境,使用 cat trace 查看函数调用茶庄统计情况。echo function > current_tracer
uboot:arm 用 uboot,体积小,flash 有限。
grub:x86 喜欢用,体积大,功能多。
本机精确查看三级 cache 的方法,可能只针对 x86:
1 | root@gedu-VirtualBox:/sys# find -name level |
lscpu 看的没法验证
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072K
stack 大小设置,上限,如何避免 stackflow,没有探讨清楚??